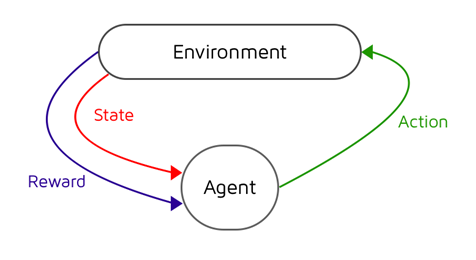
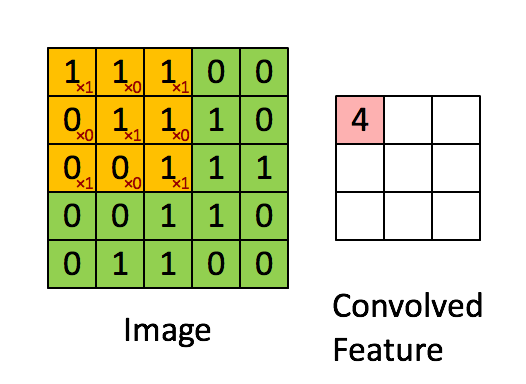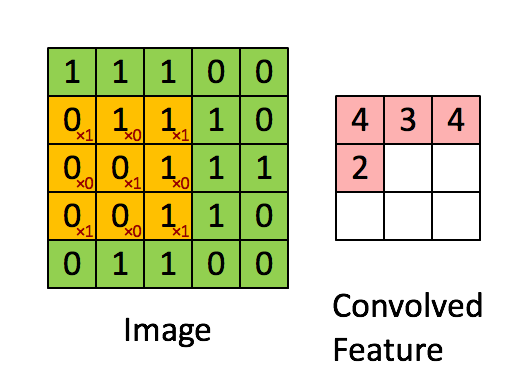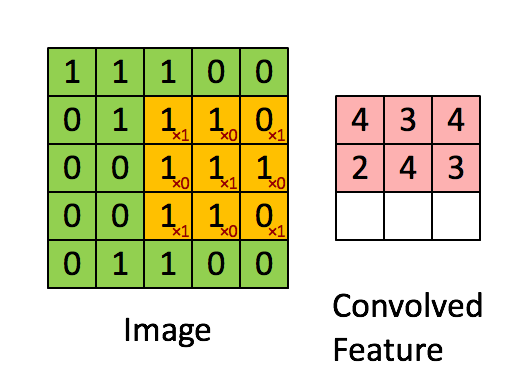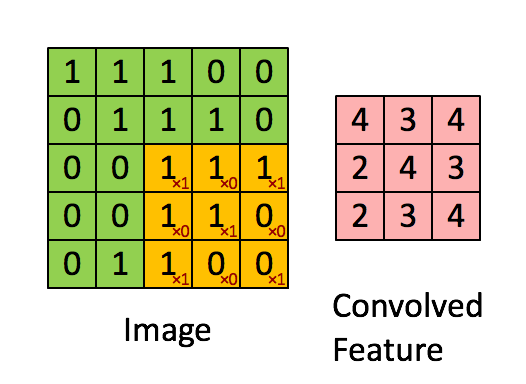
Over the last few posts we introduced the topic of Q-Learning and Deep Q-Learning in the field of reinforcement learning. We looked at how we can use the Bellman Equation to calculate the quality of taking a particular action at a given state. We originally used a Q-table to keep track of our state action pairs and eventually replaced it with a neural network to handle a larger state space by approximating our Q-values, rather than storing them for every possible state action pair.
We’ll improve on our last tutorial of building a deep Q-network for the CartPole game, by throwing in a preprocessing step that allows us to learn from image data, rather than just the handy values we get back from OpenAI’s gym library. We’ve covered convolutional neural nets before, but if you’re not familiar, I would recommend brushing up on them first, as well as the past two posts on Q-Learning and Deep Q-Learning.
In this post, we’ll combine deep Q-learning with convolutional neural nets, to build an agent that learns to play Space Invaders. In fact, our agent can learn to play a wide variety of Atari games, so feel free to swap out Space Invaders for any game listed here: https://gym.openai.com/envs/#atari
Let’s recap
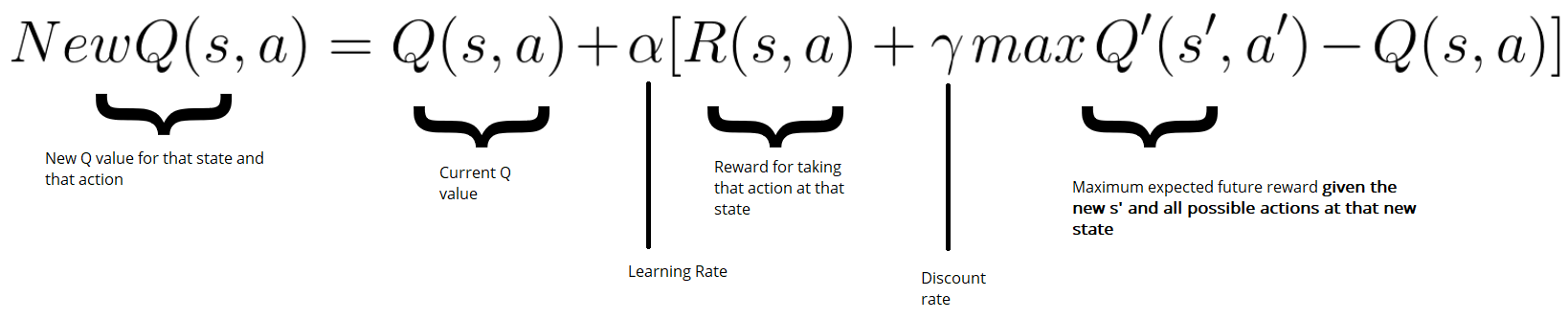
The bellman equation let’s us assess the q-value (quality) of a given state action pair. It states that the quality of taking an action at a given state, is equal to the immediate reward, plus the maximum discounted reward of the next state.
Q(s, a) = r + γ maxₐ’(Q(s’, a’))
In other words, we’ll use a neural network to predict what action gives us the biggest future reward at any given state, by not only looking at the immediate state, but also, our prediction for the one that comes after it.
Initially, we know nothing about our game environment, so we need to explore it by making random moves and observing the outcome. After a while, we’ll start slowly moving away from this exploration approach and into an approach of exploiting our predictions, in order to improve them and win the game.
If we exploit too early, we won’t get chance to try new novel ideas which could improve our performance. If we explore too much, we won’t make progress. This is known as the exploration vs exploitation tradeoff.
Experience Replay
In our last post we introduced the concept of experience replay. Experience replay helps our network to learn from past actions. At each step, we’ll take our observation and append it to the end of a list (which we’ll call our ‘memory’). We implement the list as a deque in python, a double ended queue of fixed size that automatically removes the oldest element every time we add something new to the list. We’ll then feed this minibatch into our network to train our predictions of Q values. As our network improves, so do our experiences, which feeds back into our network.
Last time we used a relatively short memory, but this time, we’re going to store the last one million frames of gameplay.
Convnet
We’ll swap out our standard neural network for a convolutional neural network and learn to make decisions based on nothing but the raw pixel data of our game. This means that our agent will have to learn what is an enemy, what is a ball, what shooting does, and all other possible actions and consequences. The advantage of this is that we’re no longer tied to a game. Our agent will be able to learn a wide variety of Atari games based purely on pixel input.
Our convnet architecture if pretty standard, we’ll have three convolutional layers, a flatten layer, and two fully connected layers. The only difference is the we’ll omit the max pooling layers.
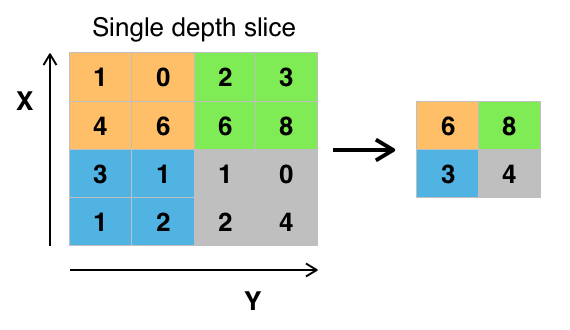
Max Pooling aims to make our network insensitive to small changes in the positions of features within our image. As our agent needs to know exactly where things are in our game, we’ll get rid of the traditional max pooling layers in our convnet all together.
Stacked Frames
When we feed our frames into our convnet, we’ll actually use a stack of 4 frames. If you think about a single frame of a game of Pong, it’s impossible to know the direction the ball is going in or how fast. Using a stack of four frames gives us a sense of motion and speed that is necessary for our network to have the full picture. You can think of it like a mini video clip being fed to our network. Instead of our input being a single frame of the shape (105,80,1), we’ll now have four channels, taking the shape to (105,80,4).
Frame Skipping
In their original paper, DeepMind skipped four frames every time they looped through gameplay. Their reasoning for doing this was that the environment doesn’t change much between single frames, we’d get a better representation of speed and movement by only looking at every fourth frame, plus we would reduce the amount of frame we need to process.
We’ll use frame skipping in our implementation, but how do we implement it? Fortunately this has been taken care of in OpenAI’s gym library.
Maximize your score in the Atari 2600 game MsPacman. In this environment, the observation is an RGB image of the screen, which is an array of shape (210, 160, 3) Each action is repeatedly performed for a duration of kkk frames, where kkk is uniformly sampled from {2,3,4}{2, 3, 4}{2,3,4}.
The version number at the end of most games (gym.make('MsPacman-v4')) isn’t a version number at all, but refers to the amount of frames we skip. We can skip anywhere from no frames, to four frames by amending the number at the end of our environment name. For example…
- MsPacman-v0 = No frame skipping
- MsPacman-v2 = Look at every second frame
- MsPacman-v3 = Look at every third frame
- MsPacman-v4 = Look at every fourth frame
Performance
Storing a million frames of pixels in memory can be quite computationally expensive. Our arrays for a single frame are 105 by 80 pixels, that’s 8400 pixels per frame. The numpy default array stores each of these pixels as a 32 bit float, meaning that our total memory (8400 * 32bits * 1000000) could take up to 33.6 gigabytes of RAM!
To combat this, we’ll specify our datatypes as uint8 for our frames and convert them to floats at the last minute before we feed them into our network. This will bring our RAM usage down from 33.6 to 8.4 gigabytes, much better!
Building our DQN
Let’s start by importing our dependencies…
import numpy as np
from keras import Sequential
from keras.layers import Dense, Flatten
from keras.layers.convolutional import Conv2D
from keras.optimizers import Adam
from keras.callbacks import ModelCheckpoint
from collections import deque
import gym
import random
Next we’ll define our DQNetwork class. I’ll keep indentation consistent, but I’ll break up some of the code so that we can walk through it block by block and really understand what’s happening.
class DQNetwork:
def __init__(self, env):
self.env = env
self.state_size = env.observation_space.shape[0]
self.action_size = env.action_space.n
self.memory = deque(maxlen=1000000)
self.stack = deque([np.zeros((105,80), dtype=np.uint8) for i in range(4)], maxlen=4)
self.gamma = 0.9
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.00003
self.learning_rate = 0.00025
self.batch_size = 64
self.frame_size = (105, 80)
self.possible_actions = np.array(np.identity(self.action_size, dtype=int).tolist())
self.model = self.build_model()
Our __init__ method is mostly the same as our last model. We’re setting up some key parameters to use later, like our gamma, epsilon (exploration vs exploitation trade off), our deque for our memory, and building and storing our model.
The new things are…
stack- A smaller deque to help stack our four frames together to show our network a sense of motionpossible_actions- One hot encoded list of our possible actions (will come in handy later)frame_size- The size of our preprocessed frames. It makes sense to abstract this out as we’ll be typing this a lot
Next we’ll need to think about preprocessing our frames before feeding them into our network. We’ll greyscale them as colour doesn’t add any additional information to our network and would take up three times the space (red, green and blue channels as opposed to a single greyscale channel). Notice we’re storing our frames as uint8 and not normalizing our frames to be between 0-1 (which we would traditionally do to prepare our data for our network). Instead, we’ll normalize on demand later on to save memory.
def preprocess_frame(self, frame):
"""Resize frame and greyscale, store as uint8 and normalize on demand to save memory"""
frame = frame[::2, ::2]
return np.mean(frame, axis=2).astype(np.uint8)
We’ll also need a method to append a frame to the end of our four frame stack deque that we defined earlier. Our deque will handle removing the oldest frame, but there is an exception that we need to handle. At the beginning of our game, we’ll need to stack the same frame four times to fill out our stack. We’ll have our method take an optional reset=True parameter that clears the stack and adds the same frame four times. Our final stacked state that we pass into our network will end up being of the shape (105,80,4).
def append_to_stack(self, state, reset=False):
"""Preprocesses a frame and adds it to the stack"""
frame = self.preprocess_frame(state)
if reset:
# Reset stack
self.stack = deque([np.zeros((105,80), dtype=np.int) for i in range(4)], maxlen=4)
# Because we're in a new episode, copy the same frame 4x
for i in range(4):
self.stack.append(frame)
else:
self.stack.append(frame)
# Build the stacked state (first dimension specifies different frames)
stacked_state = np.stack(self.stack, axis=2)
return stacked_state
We’ll need to create a similar method to store our experiences in memory, and retrieve a random minibatch…
def remember(self, state, action, reward, new_state, done):
self.memory.append((state, action, reward, new_state, done))
def memory_sample(self, batch_size):
"""Sample a random batch of experiences from memory"""
memory_size = len(self.memory)
index = np.random.choice(np.arange(memory_size), size=batch_size, replace=False)
return [self.memory[i] for i in index]
Next, we’ll build our model. This is almost identical as last time, except that we’re using the Conv2D layer from Keras, and exclusing the traditional max pooling layer that we’d normally add with a convolutional network. (Remember, max pooling makes our network insensitive to position changes. Great for object detection and classification, but not great when our game depends on the position of the features we detect!)
def build_model(self):
"""Build the neural net model"""
model = Sequential()
model.add(Conv2D(32, (8, 4), activation='elu', input_shape=(105, 80, 4)))
model.add(Conv2D(64, (3, 2), activation='elu'))
model.add(Conv2D(64, (3, 2), activation='elu'))
model.add(Flatten())
model.add(Dense(512, activation='elu', kernel_initializer='glorot_uniform'))
model.add(Dense(self.action_size, activation='softmax'))
model.compile(loss='mse', optimizer=Adam(lr=self.learning_rate))
return model
Our agent will need to be able to make two types of move, depending on where we are in our exploration vs exploitation journey. We’ll write a method that returns a random action, and a method which takes in our state (105,80,4), and predicts the best action (according to our neural network).
Notice in the predict_action method, we first divide by 255 to normalize our values between 0 and 1. Secondly, we’ll reshape our state from (105,80,4), to (1,105,80,4), a necessary step for keras to consume our data. You can think of our shape like this: (number of examples, height, width, depth). Our network will return a vector the size of our possible actions, from which, we’ll return the index of the action we predicted, ready to feed into our env.step call.
def random_action(self):
"""Returns a random action"""
return random.randint(1,len(self.possible_actions)) - 1
def predict_action(self, state):
"""Returns index of best predicted action"""
state = state / 255
state = state.reshape((1, *state.shape)) # Reshape our state to a single example for our neural net
choice = self.model.predict(state)
return np.argmax(choice)
With our random_action and predict_action methods defined, we can now write a function to select which one to choose depending on where we are on our explore vs exploit spectrum.
We’ll also use a slightly different way of calculating our explore vs exploit probability depending on the step in our game play. Lastly, we’ll return our explore_probability to log out later.
def select_action(self, state, decay_step):
"""Returns an action to take with decaying exploration/exploitation"""
explore_probability = self.epsilon_min + (self.epsilon - self.epsilon_min) * np.exp(-self.epsilon_decay * decay_step)
if explore_probability > np.random.rand():
# Exploration
return self.random_action(), explore_probability
else:
# Exploitation
return self.predict_action(state), explore_probability
Training
With the majority of our agent built, there’s only one more method to implement; training our model with experiences from our replay memory.
Firstly, we’ll check to see if our memory is less than our batch size of 64. If we don’t have enough experiences logged yet, we’ll exit the function and let our agent keep gathering random experiences until we have enough experience to form a complete minibatch to train on.
Next we prepare our minibatch. First we’ll select a random minibatch of 64 experiences, notice we also divide our states_mb and next_states_mb by 255 to normalise our frames to be between 0 and 1. Next, we’ll grab our predictions for our current state (shape (64, 105, 80, 4)), as well as the predictions for our next states.
With our predictions, we can assemble a corresponding list of the Q-values for each state. If we’ve reached a terminal state, and the game is over, then our Q-value is equal to the final reward (as there are no more future rewards). If we’ve not yet reached the end of our game, then our Q-value is set to the immediate reward (from the rewards_mb[i] list, plus the maximum discounted future reward (gamma * the maximum reward from our next state prediction).
Once we’ve finished our corresponding Q-values list, we can fit our model for one epoch, with our states_mb as our input, and our targets_mb as our labels. A single iteration doesn’t seem much here, but remember we’ll be calling this replay method at every step throughout our gameplay.
def replay(self):
if len(self.memory) < self.batch_size:
return
# Select a random minibatch from memory
minibatch = self.memory_sample(self.batch_size)
# Split out our tuple and normalise our states
states_mb = np.array([each[0] for each in minibatch]) / 255
actions_mb = np.array([each[1] for each in minibatch])
rewards_mb = np.array([each[2] for each in minibatch])
next_states_mb = np.array([each[3] for each in minibatch]) / 255
dones_mb = np.array([each[4] for each in minibatch])
# Get our predictions for our states and our next states
target_qs = self.model.predict(states_mb)
predicted_next_qs = self.model.predict(next_states_mb)
# Create an empty targets list to hold our Q-values
target_Qs_batch = []
for i in range(0, len(minibatch)):
done = dones_mb[i]
if done:
# If we finished the game, our q value is the final reward (as there are no more future rewards)
q_value = rewards_mb[i]
else:
# If we havent, our q value is the immediate reward, plus future discounted reward (gamma is our discount)
q_value = rewards_mb[i] + self.gamma * np.max(predicted_next_qs[i])
# Fit target to a vector for keras (represent actions as one hot * q value (q gets set at the action we took, everything else is 0))
one_hot_target = self.possible_actions[actions_mb[i]]
target = one_hot_target * q_value
target_Qs_batch.append(target)
targets_mb = np.array([each for each in target_Qs_batch])
self.model.fit(states_mb, targets_mb, epochs=1, verbose=1) # Change to verbose=0 to disable logging
Training our DQN
With our DQNetwork class complete, we just need to train our model. As we’ve dramatically increased our state space, our model is going to take quite a long time to train. We’re training for around 2.5 million frames of game play (50 episodes, each with a maximum of 50,000 steps per game), a conventional laptop isn’t going to cut it here (unless you’ve got a lot of RAM and are happy to leave it running for a week or two!).
I’ve included a section about my recommendations for training on an AWS instance below. But first, let’s talk about what’s happening in our training loop.
We’ll start by initialising our environment, as well as a monitor wrapper which will record each episode to video for us to review later. We’ll loop through our episodes, taking a maximum of 50000 steps per game.
At each step, we’ll pick an action based on exploration/exploitation and observe the reward and new state. We’ll append these to our memory, as we’ll need them to train on later.
If it turns out we’ve finished our game and are at the terminal state, we’ll create a blank frame to represent our next_state add to our stack. This let’s us record the final reward, if we didn’t stack a blank frame, we’d lose all the information and rewards we were awarded at the final state.
If we’re still playing our game, we’ll add our frame to the end of our four frame stack, set the state equal to the next_state to move the game on, and train our agent on a random minibatch of 64 previous experiences.
env = gym.make('Pong-v4')
env = gym.wrappers.Monitor(env, './videos/', video_callable=lambda episode_id: True) # Save each episode to video
agent = DQNetwork(env)
episodes = 50
steps = 50000
decay_step = 0
for episode in range(episodes):
episode_rewards = []
# 1. Reset the env and frame stack
state = agent.env.reset()
state = agent.append_to_stack(state, reset=True)
for step in range(steps):
decay_step += 1
# 2. Select an action to take based on exploration/exploitation
action, explore_probability = agent.select_action(state, decay_step)
# 3. Take the action and observe the new state
next_state, reward, done, info = agent.env.step(action)
# Store the reward for this move in the episode
episode_rewards.append(reward)
# 4. If game finished...
if done:
# Create a blank next state so that we can save the final rewards
next_state = np.zeros((210,160,3), dtype=np.uint8)
next_state = agent.append_to_stack(next_state)
# Add our experience to memory
agent.remember(state, action, reward, next_state, done)
# Save our model
agent.model.save_weights("model-ep-{}.h5".format(episode))
# Print logging info
print("Game ended at episode {}/{}, total rewards: {}, explore_prob: {}".format(episode, episodes, np.sum(episode_rewards), explore_probability))
# Start a new episode
break
else:
# Add the next state to the stack
next_state = agent.append_to_stack(next_state)
# Add our experience to memory
agent.remember(state, action, reward, next_state, done)
# Set state to the next state
state = next_state
# 5. Train with replay
agent.replay()
Training on EC2
I opted to train my model using a p2.xlarge instance on EC2. I ran the code as a regular python file, within a tmux session. That way I could detatch from the session and it would keep running. If you were to try running this inside a Jupyter notebook, the code would stop running as soon as you closed your browser or laptop, given that this can take days or weeks to train, it’s best to have an environment you can completely detatch from and come back to later.
You can follow this tutorial to get Jupyter Notebook up and running on an EC2 instance with GPU (follow up to the jupyter part to get your EC2 instance running):
https://medium.com/@margaretmz/setting-up-aws-ec2-for-running-jupyter-notebook-on-gpu-c281231fad3f
Once you’ve set up your EC2 instance, you’ll need to ssh into your instance, install some dependencies and download the roms for the Atari games…
sudo apt install unrar
sudo apt install ffmpeg
Download and import Atari roms…
wget http://www.atarimania.com/roms/Roms.rar
unrar x Roms.rar && unzip Roms/ROMS.zip
pip install gym gym-retro gym[atari]
python -m retro.import ROMS/
Results
Here’s Playing at episode 1. Some times we’ll hit the ball accidentally, but we’re still in the explore phase, so a lot of our movement is random and jittery.

Updates coming over the next few days as training completes!
Resources
Here are a couple of articles that really helped me with wrapping my head around the implementation of this…
https://ai.intel.com/demystifying-deep-reinforcement-learning/#gs.AfY3CNJe
https://becominghuman.ai/lets-build-an-atari-ai-part-1-dqn-df57e8ff3b26
https://medium.com/@margaretmz/setting-up-aws-ec2-for-running-jupyter-notebook-on-gpu-c281231fad3f
]]>